
小鹏 G6 的表现,完全出乎我的意料。
单一车型订单据说已经突破 5 万, 而提车周期也来到了 8 周以上。
靠着核心卖点智能驾驶和 800V 续航无补能焦虑,小鹏 G6 已经初步显露爆款特质,甚至超过一半的用户选择了带城市导航辅助驾驶的 Max 版本。
用订单数据一举打破自动驾驶无用论。
那么,作为自动驾驶量产头部企业,小鹏自动驾驶团队,做对了什么?
恰巧CVPR2023, OpenDriveLab(也就是CVPR Best Paper 相关团队)邀请了Patrick Liu(小鹏自动驾驶感知负责人)发表了题为 「The Practice of Mass Production Autonomous Driving in China」(中国量产自动驾驶的工程化实践)的演讲,里面详细描述了小鹏自动驾驶团队如何快速迭代,并且将城市导航辅助驾驶成功落地。
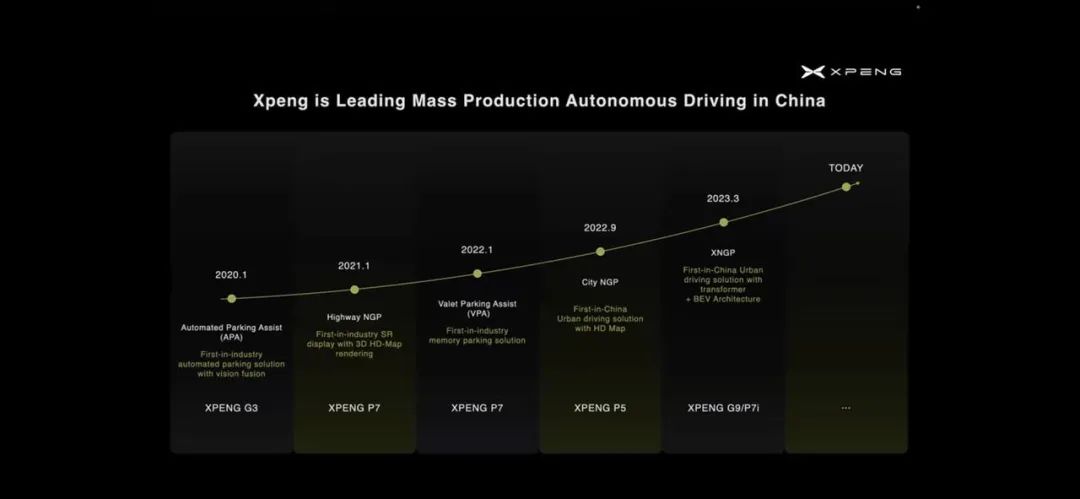
从小鹏 G3 的泊车到 P7 的高速导航辅助驾驶、记忆泊车,再到激光雷达首次上车带来的 P5 的初代城市 NGP 和最近的基于 BEV
Transformer 架构的城市 NGP,每次自动驾驶新功能发布的水准都可圈可点,迭代的速度不容小觑。
在整个高阶辅助驾驶技术栈量产落地中国的过程中,小鹏积累了哪些经验?
01
中国的高阶辅助驾驶难在哪里

每个国家的路况都不一致,相较于美国更加规则化的道路,国内的道路建设相对复杂,存在大量人车混行的情况,同时,也有非常多中国特色的信号灯系统,而这些都在极大挑战城市辅助驾驶的稳定性。
Patrick 举了大量关于左转的案例,毕竟实际上,左转的难度是系统中几乎最高的。
左转信号灯

信号灯的实时检测是 NGP 实现的第一步,如何实时识别信号灯,信号灯与道路的对应关系如何保证正确?
Patrick 举了大量关于国内红绿灯的例子用来佐证场景的复杂,但是并没有给一个关于信号灯识别具体方法论。
不过我还是很好奇不常见的这些信号灯如何识别的。
技术栈是否还是信号灯的位置被划分出来之后,再用专用的小网络分辨具体的行为意图,例如直行或者左右转,等待。
不同城市的信号灯差异会让城市辅助驾驶推广的早期成本很高,例如一般城市的信号灯都是垂直的,但是某个城市也可能出现平行于地面的。
这会让整个识别网络失效率非常高。
在城市辅助驾驶驾驶逐步开放的过程中,一定有着一个测试车队在预先收集对应城市的数据,并且进行测试。
左转待转区

这几乎是中国特色的道路结构,这让车辆的动作被分解成了两部分,先是遇到直行绿灯后,进入待转区,再遇到左转绿灯之后执行左转。
这涉及到特色道路拓扑结构的的新的理解,还有和信号灯语义的精准对齐。
这与高速导航辅助驾驶的技术是完全不同的,难度也与清晰明朗的匝道上下不可同日而语。
很多高阶辅助驾驶公司还在这里挣扎,看上去,小鹏城市NGP这个问题已经基本上收敛了。
不过,目前还是基于高精地图的版本,道路的理解难度并不算高。
期待无图版本。
02
模型虽好,但工程化更重要
整体来看,这套 BEV 的算法模型与 Tesla 的区别并不大,也能够部署到两块 Orin 芯片上。
系统是业界公认的架构,摄像头进入 BackBone 之后获得特征表达,并且映射到 BEV 空间,同时融合空间信息和时序信息。
这样能够对一些被遮挡的位置进行脑补,满足视线常常不好的城市导航辅助驾驶的需要。

其实整个小鹏的感知模型技术栈发生了巨大的变化,从 Perception 1.0 的 2D 图识别在进入融合模块,然后投影到 3D 空间,到现在从图片直接出来 3D 表达,这也是整个自动驾驶感知行业的趋势。
而预测模块(Prediction)和规划控制模块(Planning and Control) 依然有着相对独立的模块,这也符合量产的需要。
如果将后两者也纳入一个网络中,优化的方向会非常难以寻找。不过我依然认为这是未来的趋势,例如将 Prediction 直接纳入感知大模块中,直接预测BEV3d 和轨迹信息。
其实作为有着庞大量产车队的小鹏有巨大的优势,那就是从数据中获取的海量周围车辆的轨迹信息,可以用于做某一个时刻的后验真值,来训练预测算法。
即在某一个时刻预测下一时刻某个交通参与者的轨迹信息,可以使用下个时刻记录下来的数据直接作为真值来训练。
03
小鹏自动驾驶的核心竞争力
如何在这么短的时间内完成模型的切换,并且做到量产可交付的?这是小鹏自动驾驶团队的核心竞争力。
数据闭环和自动标注系统
依托于庞大的量产车队和数据采集车队,小鹏有着非常大的数据池。
在某个不常见的场景出现时,可以直接在数据池中获取罕见的数据,用于训练算法。这解放了大量基于规则的工作,真正做到数据驱动。
例如一个很奇怪的运货小车被识别失败,这个目标会进入数据池中,并且通过图找图技术,和文找图技术(互联网相对成熟的技术,搜索引擎中很常见)在整个数据湖中进行搜寻,找到大量目标数据之后进行训练。

数据找到了之后,还需要真值,才能进行训练。
小鹏的自动标注系统将原来 2000 人每年的工作,降低到了 16.7 天。
这是很恐怖的一个数字。
一个离线的识别模型,少了车上算力的限制,可以将模型变得更大;同时多了多帧的信息,例如某一帧的自动标注可以使用前一帧和后一帧的信息来对齐,保证位置的准确性。

同时由于比特斯拉的数据多了 Lidar,标注的精度会大大提升。
自动标注系统产生的源源不断的数据是小鹏快速迭代的最重要的原因。
写在最后
我们在一个自动驾驶技术栈变化非常快的时刻,网络结构层出不穷,可能是在某个榜单上多了百分之一的准确率,或者在某个会议上大放异彩。
我看到有公司在努力用更好的网络结构,看上去更加先进的算法做自动驾驶,也看到许多工程师在不断尝试层出不穷的新方法。
但是 Patrick Liu 这次的演讲,让我觉得,小鹏自动驾驶团队真正抓住了量产落地的本质:在变化中寻找不变。
传感器都会变化,但是摄像头不会;
网络模型可能会变化,但是工程经验不会;
模型架构可能会变化,但是对数据的需求不会变;
人们对自动驾驶的态度可能会变化,但是自动驾驶的价值不变。
如果说目前的技术栈还是跟着 Tesla 的方案在进行,那我期待下一次的发布,小鹏能引领端到端的技术浪潮。
Youtube: https://www.youtube.com/watch?v=d6ucRgDDUWQ